Å spare penger på Amazon Web Services (AWS) Spot Instances kan være en utfordrende oppgave. Husk at det i bunn og grunn er en auksjon. Selv om prisene ikke svinger like raskt som på børser, kan de fortsatt øke til de når on-demand-prisen. Noen ganger varer det i en dag eller to, men andre ganger — opptil flere måneder, noe som kan doble kostnaden.
Hvordan unngår du en situasjon der for eksempel alt gikk perfekt i november, men i desember doblet prisene seg midt i høytidshysteriet — og du endte opp med ikke bare et dyrt system, men også et med avbrudd? La oss undersøke hvorfor dette skjer. For dette skal vi se på Spot Instance-allokeringsstrategier og hvordan du kan bruke Terraform-modulen uten problemer og samtidig spare penger.

En Spot Instance er en ubrukt EC2 (Elastic Compute Cloud)-ressurs som legges ut for auksjon til en minimal pris. Hovedulempen er avbrudd, så vær forberedt. Spot Instance-avbrudd er ikke uvanlige — de er en del av arbeidsflyten snarere enn en slags hendelse.
Det er tre hovedårsaker til avbrudd:
- Den nåværende prisen er høyere enn det du er villig til å betale.
- Det finnes ingen Spot Instances av typen du bruker igjen.
- Du har satt ekstra begrensninger — for eksempel når du først satte alle Availability Zones, men deretter bare lot én være igjen. Informasjon om avbrudd vil bli levert via EC2 Metadata Service og EventBridge. Disse tjenestene lar deg gjøre noe behandling, men det bør bemerkes at AWS SLA for en enkelt instans kun er 90 %, så du bør forvente avbrudd i alle instanser, ikke bare i spots.
Enkle måter å håndtere avbrudd på Lenke til overskrift
Legg til stabilitet og elastisitet Lenke til overskrift
For å gjøre Spot Instances mer stabile og robuste, bruk en Auto Scaling Group. Da, hvis du opplever et avbrudd, vil du kunne fullføre noen oppgaver eller i det minste få en ny instans som erstatter den forrige.
Øk sjansene dine for oppstart Lenke til overskrift
AWS bruker som standard forskjellige Instance Types. Men hvis du manuelt oppretter en Auto Scaling Group, vil du se en full liste over alle mulige Instance Types. Og hvis du ikke har en bestemt type, kan du bruke andre. I noen tilfeller kan du til og med bruke tidligere generasjoner. AWS har statistikk for alle Instance Types som sporer sannsynligheten for avbrudd i hver region. Derfor er det best å velge en Instance Type fra Spot Instance Advisor-tjenesten. Her vil du se hvilke typer som er bedre for hver spesifikke region. Du kan også raskt sortere dem mens du er på siden — for eksempel sortere etter hvilke som var minst påvirket av avbrudd den siste måneden.
Spot Instance-allokeringsstrategier Lenke til overskrift
Det finnes flere allokeringsstrategier. De påvirker hvor en Spot Instance vil bli startet fra og fra hvilken Spot Pool (et sett med ubrukte EC2-er innen samme Availability Zone og Instance Type).
Standardstrategi Lenke til overskrift
Standard allokeringsstrategi er capacity-optimized. Den lar deg få en Spot Instance fra en Spot Instance Pool med mest tilgjengelig kapasitet. Dessuten, når den kombineres med en Auto Scaling Group, vil det kun bli valgt én Instance Type per Availability Zone — noe som er mindre sannsynlig å feile. Dette er en veldig god strategi for belastninger som er dyre å avbryte. Men hvis du vil spare mer, finnes det et alternativ.
Laveste pris Lenke til overskrift
Denne strategien velger en Spot Instance fra flere Spot Instance Pools i hver Availability Zone med lavest kostnad per spot. Du kan til og med spesifisere antall spots å velge fra. Standard er to, men du kan sette opptil 20. Dette fungerer også godt med en Auto Scaling Group og instanser av flere typer, noe som betyr at vi kan få forskjellige typer instanser i forskjellige Availability Zones. Selv om det er praktisk, bør du huske at laveste pris følges av flest avbrudd. Dette er fordi vi ikke lenger har indikasjoner på hvilken Spot Pool som har minst sjanse for avbrudd.
Bærekraft med Capacity Rebalancing Lenke til overskrift
Metoden for å forbedre spot-resiliens med det nye signalet EC2 Rebalance Recommendation ble tilgjengelig i 2020. Det kan komme tidligere enn standard to minutters varsel for Spot Instance-avbrudd. Dermed lanserte EC2 Auto Scaling funksjonen Capacity Rebalancing:
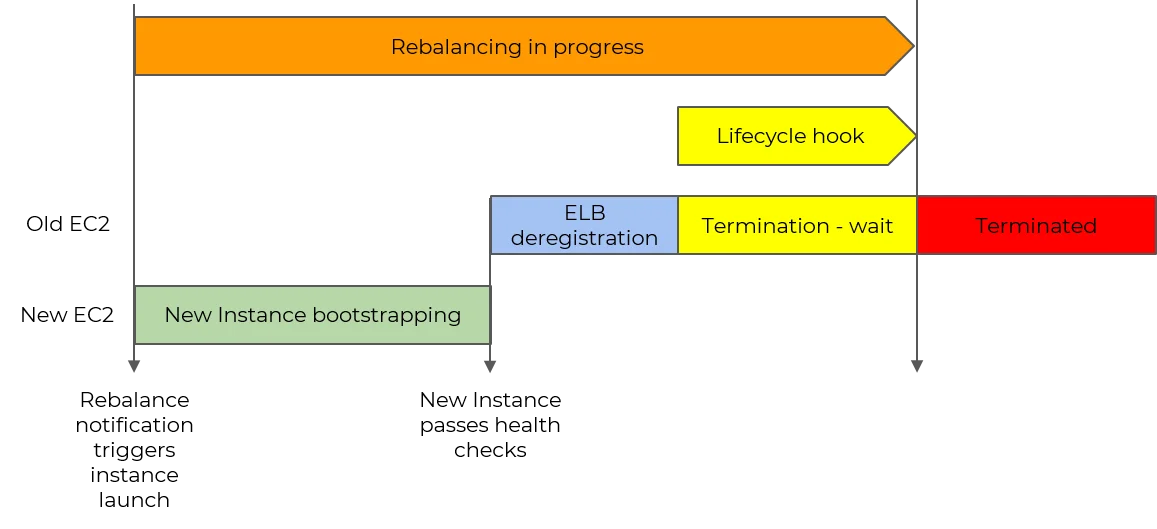
EC2 Auto Scaling Capacity Rebalancing Lenke til overskrift
La oss gå mer i detalj siden det ga mer stabilitet til spots. Først får du en melding som varsler om Capacity Rebalancing-signalet. Auto Scaling Group (eller et tredjeparts skript som har mottatt dette signalet) starter deretter en ny instans som kjører gjennom alle sine prosesser. Etter det vil instansen som har forhøyet risiko for avbrudd og som mottok Capacity Rebalancing-signalet begynne å termineres.
Det finnes endelig en måte å håndtere terminering av en Spot Instance på riktig måte. Du kan legge til Lifecycle hooks for Auto Scaling Group, sette instansen i terminating, eller ta et event fra EventBridge og kalle en Lambda-funksjon på det med en slags logikk. For eksempel, i tilfelle containerisering (ECS eller EKS), kan du fjerne alle Pods/ECS Tasks fra denne instansen og unngå å avbryte belastningen helt. Disse enkle anbefalingene kan være nok for noen. Men la oss gå videre og se hvordan du kan spare penger samtidig som du oppnår høy effektivitet.
Hvor mye koster en Spot Instance? Lenke til overskrift
Dette er sannsynligvis det viktigste spørsmålet. For å svare bruker vi et par verktøy:
- Den gode gamle Cost Explorer, med grunnleggende og tilgjengelig informasjon;
- En ekstra Spot Instance datafeed — en detaljert rapport i S3, som aktiveres i innstillingene. La oss først se på hvordan man bruker Cost Explorer. Vi har gruppert spots etter Instance Type, filtrert dem etter Usage Type Group EC2 Running Hours, og satt det viktige valget kalt Purchase Option Spot. Som resultat får vi to grafer: Kostnader og Bruk:
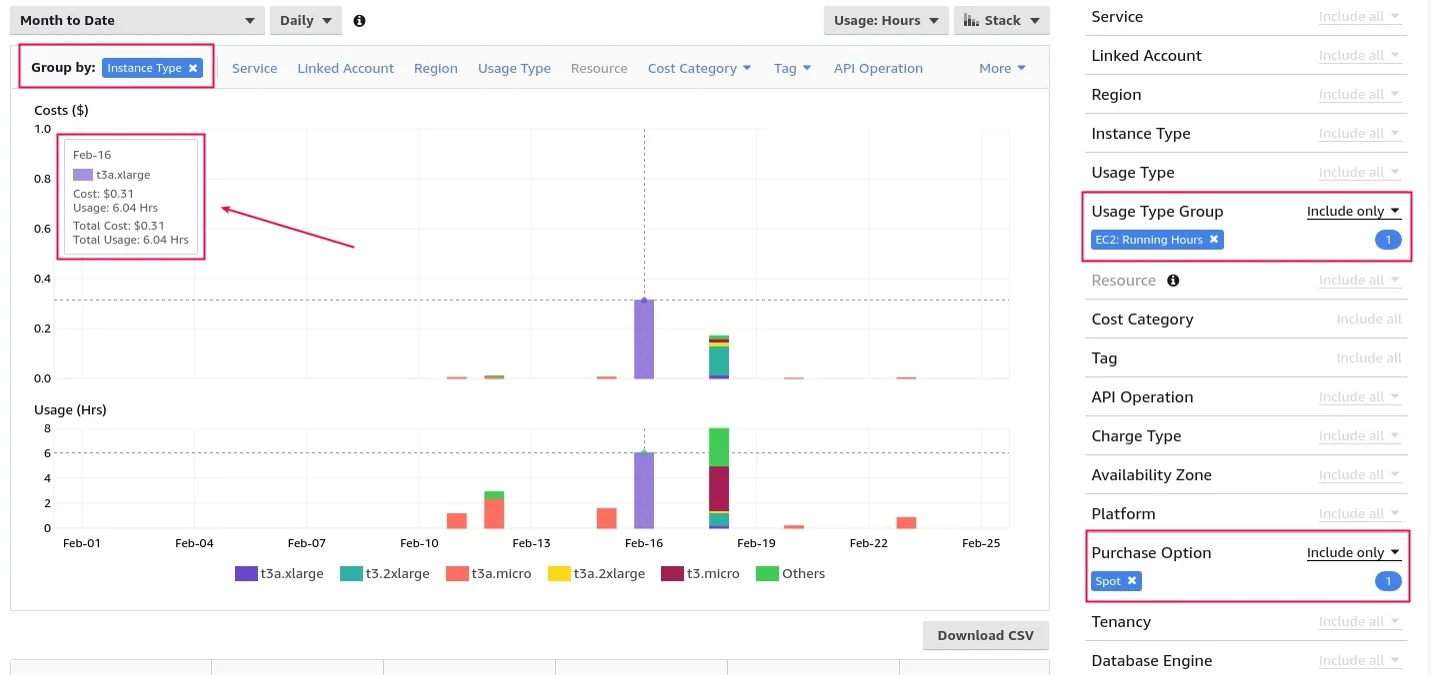
Teknisk sett kan de brukes til å bestemme gjennomsnittsprisen per dag — bare del den ene på den andre. Hvis du legger til filtre etter tags, kan du få en generell idé om hva som skjer. Men når du får mange forskjellige Instance Types i resultatene, blir det vanskeligere. Dessuten finnes det ikke detaljert allokering per time som standard. Selvfølgelig kan det inkluderes i Cost Explorer, men det er ikke nødvendig for denne oppgaven, og det er heller ikke gratis. Derfor skal vi nå se på Spot Instance datafeed. Ny informasjon legges til hver time, men med forsinkelser. Tester viser at forsinkelser kan vare fra 15 minutter til flere timer:
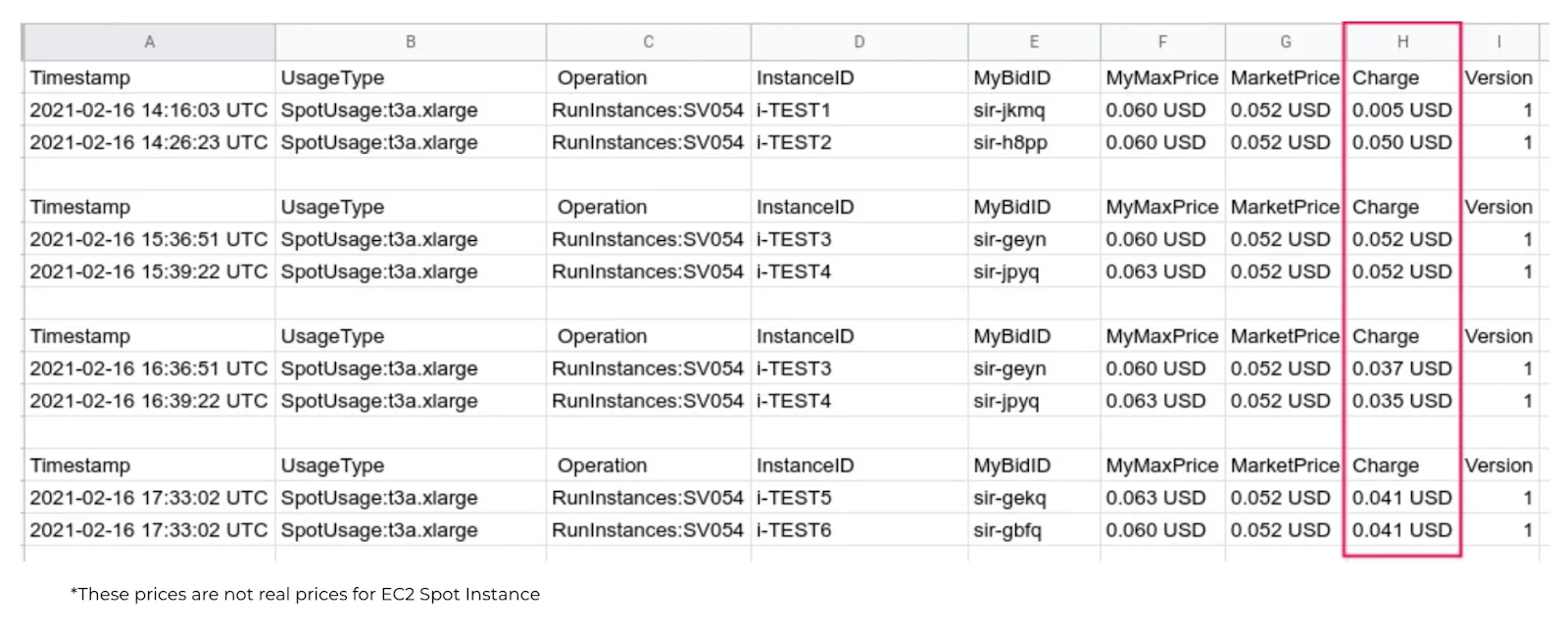
Det viktigste du kan få fra Spot Instance datafeed er detaljert informasjon med instanstype, maksimal pris, gjeldende markedspris og til slutt prisen du betalte (Charge-kolonnen). Når det gjelder oppsett, trenger du en litt tilpasset ACL for S3, selv om det ikke vil være problemer med det.
Innstillinger for Spot Instance Data Feed Lenke til overskrift
Den nåværende prisen kalles Spot Price (Charge-kolonnen). Denne prisen settes per Availability Zone og Instance Type basert på tilbud og etterspørsel på Amazon. Den justeres gradvis basert på langsiktige prognoser. Det er imidlertid verdt å merke seg at dynamikken i prisendringer oppover og nedover er ganske jevn — noe som betyr at prisene ikke endres time for time, og hvis det er $1 en dag, vil det ikke være $3 neste dag.
Derfor kan du bruke en viktig, men mindre kjent innstilling kalt Spot Max Price. Dette er maksimalprisen du er villig til å betale for en Spot Instance. Så snart den når et høyere nivå, slutter du rett og slett å betale. Folk har ofte mislyktes i å konfigurere Spot Max Price fordi det ikke var inkludert i UI, og brukere måtte sette det gjennom SLA. Men siden den gang har det blitt lagt til i Spot-forespørselen.
Å sette Spot Max Price er veldig viktig. Hvis du ikke spesifiserer noen verdi, godtar du automatisk å betale hvilken som helst pris opp til on-demand (som i praksis er pristaket). For eksempel, se på prisdynamikken i løpet av desemberhøytiden for tre forskjellige Instance Types:
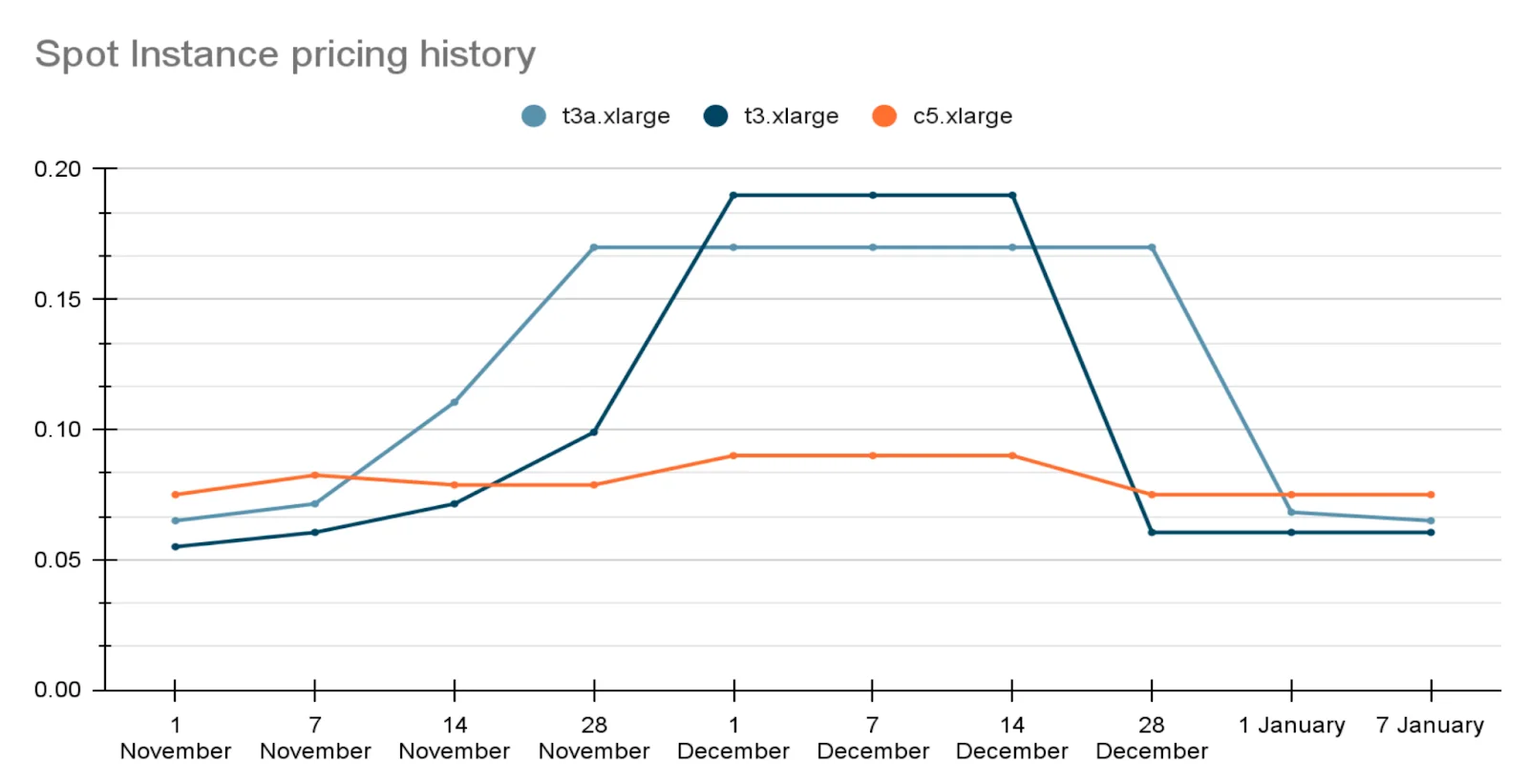
Først var den mest kostnadseffektive typen t3a, men siden den er omtrent 10 % billigere i gjennomsnitt, begynte etterspørselen etter den å vokse. Folk begynte å kjøpe den i raskt tempo, og på et tidspunkt ble t3 mer kostnadseffektiv. Og da folk kjøpte den opp, ble c5 billigere, noe som var ganske uventet.
Husk at en type A Spot Instance ofte er dyrere enn vanlige. Den vanlige årsaken er deres popularitet — de er billigere on-demand og kjøpes oftere. Du tenker kanskje — hva bør du gjøre da? Droppe Spot Instances helt? Vel, ikke hast. Det finnes en løsning — Terraform-modulen vil hjelpe deg å løse de fleste av disse problemene uten at du må overvåke spot-prishistorikken kontinuerlig.
Terraform-modulen Lenke til overskrift
Modulen løser problemet med å automatisere hvordan Spot Max Price beregnes. Den har flere atferder som kan være nyttige:
- spot_price_current_min — minst én Instance Type i minst én AZ;
- spot_price_current_optimal — minst én Instance Type i alle AZ-er;
- spot_price_current_max — alle Instance Types i alle AZ-er;
- spot_price_current_max_mod — alle Instance Types i alle AZ-er med økt pålitelighet. La oss gå gjennom dem fra enkel til kompleks ved å bruke prismatrisen som eksempel:
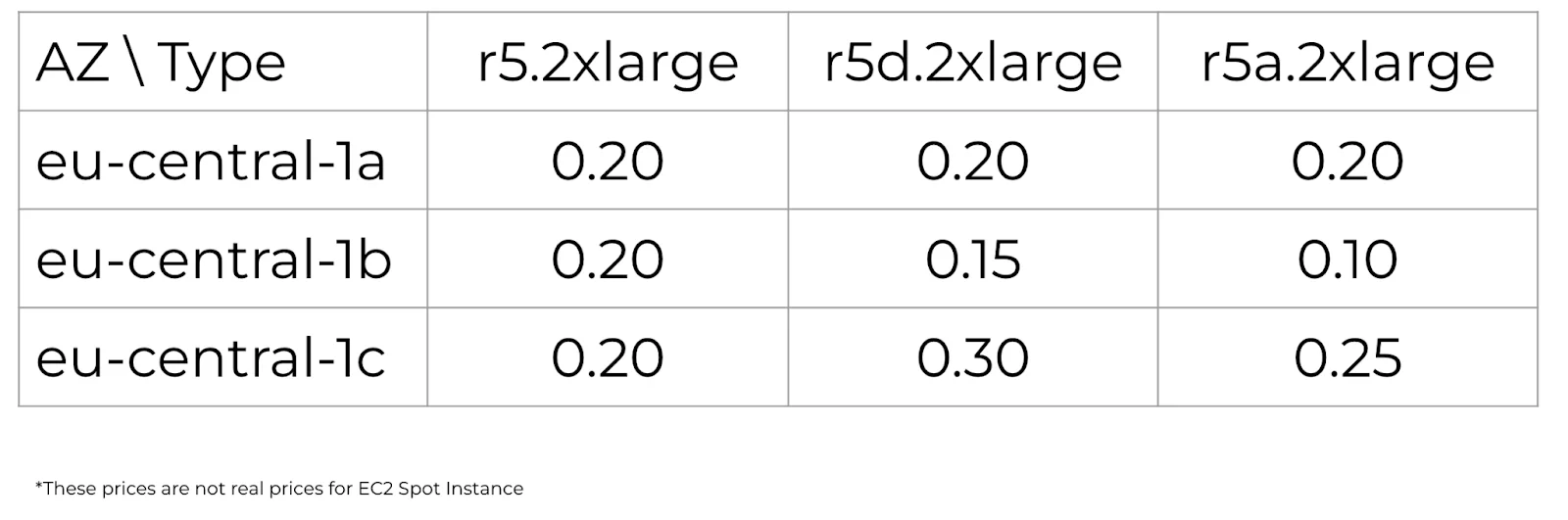
Først får vi den nåværende spot_price uten å åpne UI og Spot price history. Dette er det enkleste eksempelet:

Minimumspris Lenke til overskrift
Dette er et litt mer komplekst eksempel hvis målet ditt er å kjøre den billigste instansen mulig. I denne situasjonen bruker du spot_price_current_min-atferden:

I dette tilfellet vil instanser av minst én Instance Type bli startet i én Availability Zone. Men selv om flere Availability Zones er angitt, ender alle instanser opp i samme sone fordi bare én velges. Husk at det alltid bare er én instans som er billigst.
Ser vi på tabellen vår, kan vi se at det kun finnes én instans av typen r5a i Availability Zone 1b med minimumspris på 0,10. Når prisene endres, vil du motta laveste pris hver gang. For eksempel, hvis prisen begynner å øke i én Availability Zone, vil du neste gang du kjører terraform apply få den neste minimumsprisen, for eksempel fra en annen Availability Zone. Selvfølgelig vil denne atferden føre til avbrudd oftest, og hvis prisen øker selv litt, mister du umiddelbart denne instansen. Derfor er denne atferden ikke veldig effektiv. En bedre tilnærming er å finne balansen mellom pris og tilgjengelighet.
Optimal pris Lenke til overskrift

Denne atferden gjør det mulig å kjøre minst én Instance Type i alle Availability Zones, noe som løser problemet med å avgjøre hvilken Instance Type som er mest kostnadseffektiv: t3, t3a, c5 eller noen av r-typene. Når prisene endres, bytter du til de mest kostnadseffektive Instance Types for hver Availability Zone. Hvis prisene stiger, mister du én Availability Zone om gangen, akkurat som når du deaktiverer dem. Tilbake til tabellen vår ser vi mange flere alternativer:
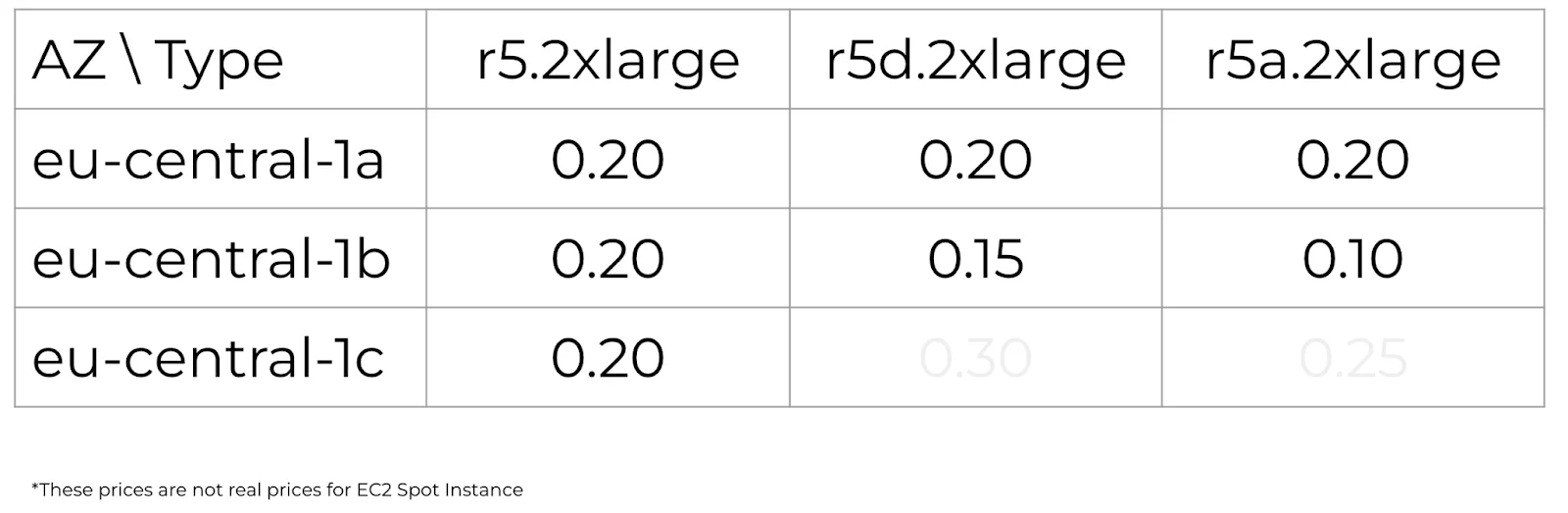
Kun r5-instanser vil være tilgjengelige i Availability Zone 1c til 0,20. Men hvis de øker til 0,30, vil du fortsatt ha to flere Availability Zones og to andre Instance Types. Viktig merknad: en slik overføring vil avbryte arbeidet til de instansene hvis priser har økt. Men når det gjelder spots, må du alltid være forberedt på avbrudd og betrakte dem som vanlig.
Alle de tidligere alternativene fokuserte på høyest mulig besparelse, men hvis du trenger mer stabilitet, vil spot_price_current_max-atferden gjøre jobben.
Maksimal nåværende pris Lenke til overskrift

Med denne atferden kan alle Instance Types startes i alle Availability Zones. Dette løser problemet med å ikke ha Spot Instances ved å bestemme prisen for forskjellige typer. Denne atferden tillater også stor forsinkelse mellom terraform apply, og modulen trenger ikke kjøres så ofte. Dette er spesielt praktisk hvis modulen noen ganger kjøres manuelt, ikke i CI/CD. I dette tilfellet, ifølge tabellen, kan hvilken som helst Instance Type startes i hvilken som helst AZ fordi ingen av dem overskrider maksimalprisen. Det betyr at hvis du kjører r5 i 1a, som koster 0,20, vil du betale den prisen helt til den når 0,30. Denne atferden gjør deg autonom fra alle Instance Types og Availability Zones. Hvis du legger til mange Instance Types, kan du dekke alle tilfeller og alltid ha spots.
Modifisert pris Lenke til overskrift
Hvis du trenger enda mer stabilitet, og er villig til å noen ganger betale 5-10 % ekstra, finnes spot_price_current_max_mod-atferden:

Denne atferden reduserer muligheten for avbrudd fra mindre prisvariasjoner og vil hjelpe hvis Terraform kjøres svært sjelden eller manuelt. Du kan spesifisere at du er villig til å betale på forhånd, for eksempel 10 % ekstra på toppen av gjeldende pris, altså 0,33 i stedet for 0,30. Dette er en liten ekstra kostnad for reduserte avbrudd. Husk at ekstra kostnad i stor grad avhenger av antall instanser du bruker. En forskjell på +2¢ kan utgjøre $14 i måneden per EC2-instans, og hvis du bruker 100 av dem, kan det bli $1 400. Derfor bør du regne på om det er verdt å redusere muligheten for avbrudd. Hvis du fortsatt mener det er verdt det, kan du bruke denne atferden på alle andre scenarier gjennom den tilpassede prismodifikatoren.
Bruksområder for EC2 Spot Price-modulen Lenke til overskrift
Det mest grunnleggende problemet Terraform-modulen løser, er at den ikke lar prisen nå taket slik at du ikke ender opp med dobbel pris. Derfor kan den brukes hvor som helst du bruker en Auto Scaling Group. Hvis du har en ECS Capacity provider, EKS-worker nodes, GitLab runners, hvilken som helst belastning som kan avbrytes, byggemaskiner, rester fra overvåking eller et DevTest-miljø — kan de kjøres helt på spots. Hvis du bruker det spesielle flagget ECS_ENABLE_SPOT_INSTANCE_DRAINING i ECS eller EKS Node Termination Handler for EKS, kan du til og med starte produksjon med en gang. Det har vært tilfeller der disse fungerte helt på spots.
Her er et mer typisk eksempel — når én eller to on-demand-instanser startes i tilfelle alt blir tatt bort. Og alt som skaleres opp, sendes via spots fordi det ennå ikke er klart hva belastningen vil bli, og ingenting kan kjøpes på forhånd.