AWS User Group Singapore Lenke til overskrift
Jeg ble invitert til AWS User Group Singapore for å snakke om PostgreSQL i AWS og om Amazon Aurora DSQL. Det var et flott arrangement. Jeg var glad for å møte mange ingeniører og arkitekter fra fellesskapet. Bruken av PostgreSQL i Singapore er ganske stor, omtrent halvparten av publikum brukte det. Organiseringen av arrangementet var perfekt. Jeg var glad for å være en del av det.

En liten historie om PostgreSQL i AWS Lenke til overskrift
Open-Source og selvadministrert PostgreSQL Lenke til overskrift
Hvorfor kaller noen det PostreSQL og noen kaller det Postgres? Svaret er enkelt. Det opprinnelige navnet på prosjektet var POSTGRES, som står for “Post Ingres.” Prosjektet ble startet på midten av 1980-tallet av et team av forskere ved University of California, Berkeley, som en etterfølger til Ingres databasesystem. Navnet ble senere endret til PostgreSQL for å fokusere på SQL-funksjonene i databasen.
PostgreSQL har utviklet seg over nesten 30 år til å bli en av de mest populære open-source relasjonsdatabasene. Dens utvidbarhet, sterke bidrag fra fellesskapet over hele verden, og aktiv utvikling har gjort den til et foretrukket valg for moderne applikasjoner.
AWS har spilt en betydelig rolle i å utvide PostgreSQLs kapasiteter. Fra tidlig støtte gjennom EC2 Relational Database AMIs til å gi store bidrag spesielt til logisk replikasjon og utvidelser som pgvector som gjør det mulig å bruke PostgreSQL som en vektordatabasen for Amazon Bedrock.

Fra RDS til Aurora: En ny æra Lenke til overskrift
Amazon RDS ble lansert i 2009, men kun for MySQL. Støtte for PostgreSQL kom i 2013. RDS tok tak i utfordringene med selvadministrerte databaser ved å introdusere funksjoner som Multi-AZ for høy tilgjengelighet, automatiserte sikkerhetskopier, opptil 3 TB lagring, og 30 000 IOPS. Disse innovasjonene forenklet livet for ingeniører og arkitekter over hele verden, og gjorde PostgreSQL i RDS til en revolusjon for mange.
I 2017 introduserte AWS Amazon Aurora PostgreSQL, under PostgreSQL 9.6-æraen. Selv om det i starten møtte skepsis på grunn av forskjeller mellom Aurora PostgreSQL og RDS for PostgreSQL, har adopsjonen vokst jevnt. I dag, med PostgreSQL versjonene 14, 16 og videre, har Aurora PostgreSQL blitt mitt standardvalg for moderne skyprosjekter. Hvis du fortsatt vurderer Amazon RDS for PostgreSQL eller Amazon Aurora PostgreSQL, vil jeg anbefale å gå for Aurora som standardalternativ.
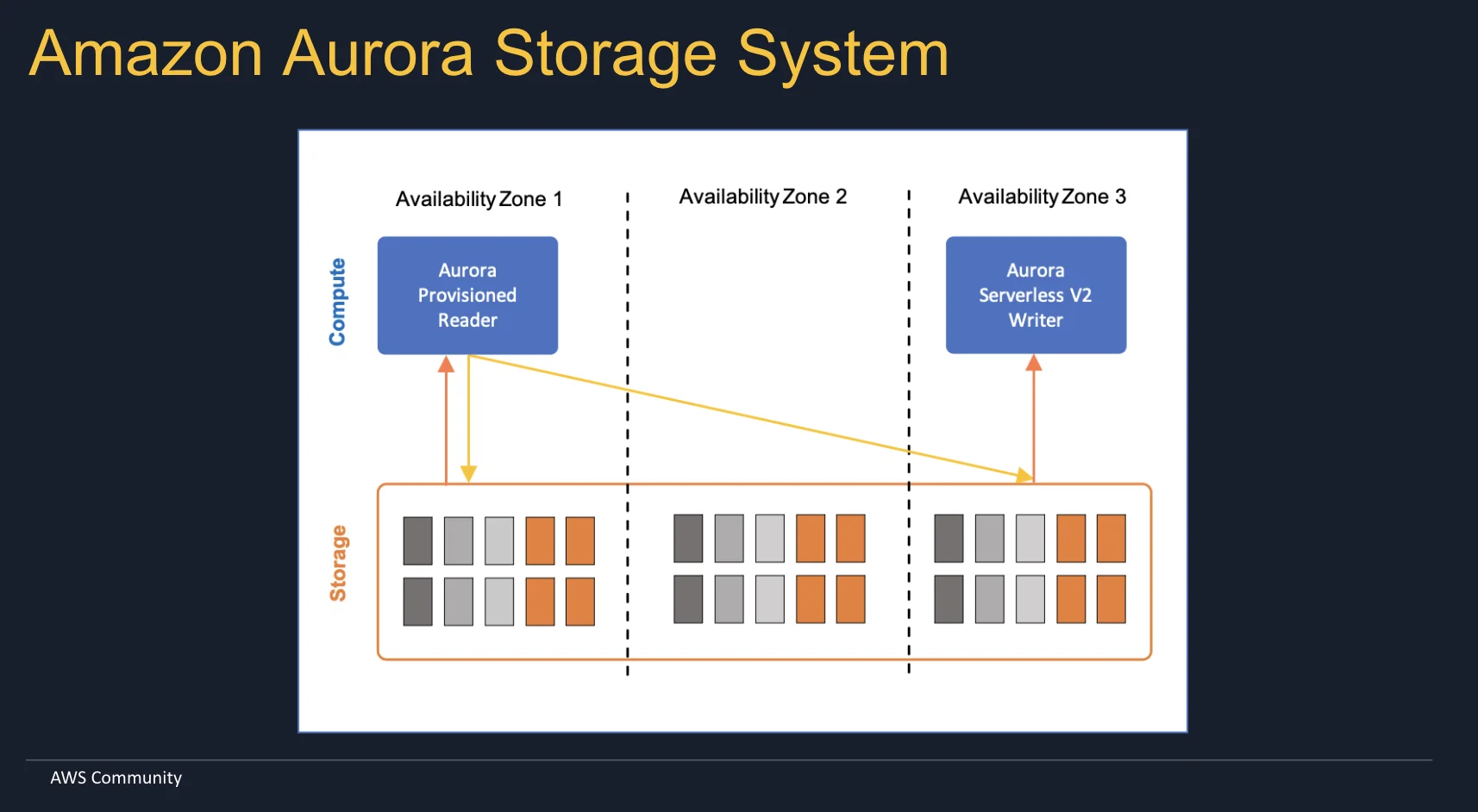
Aurora PostgreSQL brakte revolusjonerende endringer til arkitekturen. Det var den første dekomponeringen. Den loggbaserte lagringsmotoren som tillater bruk av headless klynger. Ja, dette er ekte – du kan fjerne all compute i Amazon Aurora og fortsatt beholde dataene. Nøkkelfunksjoner i Amazon Aurora PostgreSQL inkluderer:
- Shared Storage Architecture: Et distribuert, feiltolerant system hvor lagring skaleres uavhengig av compute.
- Aurora Fast Database Cloning: Muliggjør raske, plassbesparende kloner av databaser for testing og utvikling.
- Parallel Queries and Distributed Reads: Optimalisert ytelse med spørringer som kjører parallelt over flere noder og distribuerte leseoppgaver.
- Custom Endpoints: Gir fleksibilitet for ruting av spesifikke arbeidsbelastninger til bestemte klyngenoder.
- Point-in-Time Recovery: Lar brukere gjenopprette databaser til et spesifikt tidspunkt, og sikrer robusthet i katastrofesituasjoner.
Ved å separere compute og lagring, tillater Aurora PostgreSQL oss også å eksperimentere med compute-instanser. Starte forskjellige typer instanser og se hvordan det påvirker ytelsen for eksempel. Prøve forskjellige klasser, migrere fra en til en annen. Og alt dette uten å gjenskape databasen.
Aurora Serverless Lenke til overskrift

Aurora Serverless gir oss muligheten til å ikke tenke på størrelsen på compute-instansen i Amazon Aurora. Det var en versjon 1, men den er ikke aktuell lenger. v2 er den eneste som er tilgjengelig og den kan skalere til 0 også.
Kostnad er imidlertid fortsatt en bekymring. Selv om skalering til 0 kan redusere utgifter i inaktive perioder, er serverless v2 bare dyrere. Jeg kunne foreslå å hente CPU-bruksdata fra den nåværende databasen og beregne kostnaden for serverless v2.
For meg kunne jeg finne et tilfelle for Aurora Serverless v2, og det er håndtering av uforutsigbare arbeidsbelastninger som ekte kryptovalutaprissvingninger. Under markedsspisser skalerer Aurora Serverless v2 dynamisk for å møte etterspørselen uten manuell inngripen.
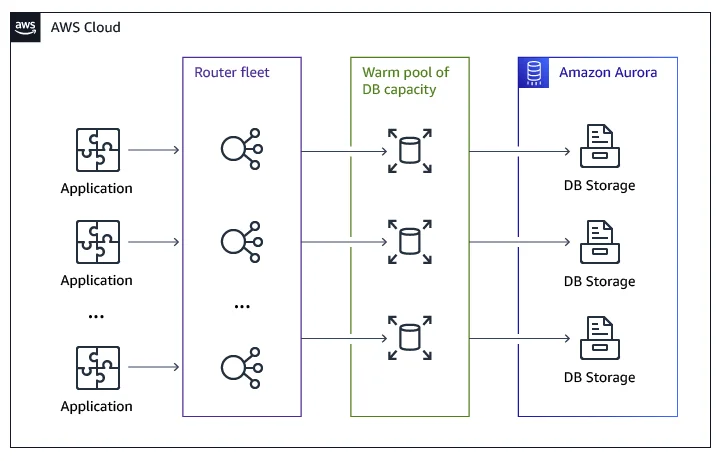
Amazon Aurora Serverless introduserer Request Routers, som legger til et tredje lag i Auroras arkitektur og fortsetter dekomponeringen:
- Request Routers: Håndterer trafikk og administrerer tilkoblinger.
- Database Instances and Compute Fleet: Skalerbare compute-ressurser.
- Shared Storage: Holdbar og frakoblet fra compute.
Amazon Aurora Global Database Lenke til overskrift
Aurora Global Database er en funksjon som lar deg opprette en enkelt Aurora-database som strekker seg over flere AWS-regioner. Denne funksjonen er nyttig for applikasjoner som krever lav ventetid til en database fra forskjellige regioner. Aurora Global Database bruker Auroras distribuerte lagringsarkitektur for å replikere data på tvers av flere regioner. Skriveoperasjoner er imidlertid begrenset til en enkelt region, mens leseoperasjoner kan distribueres over flere regioner. Siden 2024 har vi også fått Global Writer-endepunkt som tillater å omdirigere skriveoperasjoner til skriverregionen.
Viktig moment her er replikasjonsservere. En annen tilpasset komponent som tillater å replikere data mellom regionene med latens som vi kan måle i millisekunder. I mitt tilfelle er det under 50 ms. Men viktig er at vi snakker om millisekunder, ikke sekunder. Jeg tror det er veldig nær lysets hastighet.

Amazon Time Sync Service Lenke til overskrift
Kanskje ikke så kjent, men veldig viktig tjeneste. Amazon Time Sync Service er en svært nøyaktig og pålitelig tidskilde som gir gjeldende tid som Coordinated Universal Time (UTC). Og siden i fjor gir den mikrosekund-nøyaktig tid. Og den er faktisk offentlig tilgjengelig. Du kan bruke den i dine applikasjoner: time.aws.com La oss synkronisere klokkene våre over hele verden!
PostgreSQL 17 Logical Replication Lenke til overskrift
Siden PostgreSQL 17 kan vi utføre større oppgraderinger uten å fjerne replikasjonsplasser. Og det betyr at vi ikke trenger å resynkronisere data etter oppgraderingen. Og det skjer før re:Invent 2024.
I fjor jobbet jeg med logisk replikasjon og fulgte nyhetene, og på et tidspunkt begynte alt bare å falle på plass. Dekomponering av databasen, tidsynkroniseringstjeneste, forbedringer i logisk replikasjon. Ingen Google Spanner-alternativ i AWS, du vet, alle disse nyhetene burde føre til noe stort.
Amazon Aurora DSQL Lenke til overskrift
Amazon Aurora DSQL er fullstendig serverløs med null infrastrukturadministrasjon. Den leverer aktiv-aktiv arkitektur, oppnår 99,99 % tilgjengelighet i en enkelt region og 99,999 % i flerregionoppsett, og sikrer enestående pålitelighet for kritiske arbeidsbelastninger.
Aurora DSQL er optimalisert for transaksjonsarbeidsbelastninger som krever konsistens av ACID-transaksjoner. I motsetning til tradisjonelle oppsett eliminerer Aurora DSQL problemer med eventual consistency og failovers.
Aurora DSQL er det perfekte valget for moderne applikasjoner som trenger pålitelige, svært tilgjengelige og skalerbare databaseløsninger.
DSQL. Lag Lenke til overskrift
Aurora DSQL fortsetter database-dekomponeringen, men tar det faktisk til neste nivå. Dette er en flerlagsarkitektur for å optimalisere ytelse og skalerbarhet samtidig som PostgreSQL-kompatibilitet opprettholdes:
- Transaction and Session Routing: Fordeler arbeidsbelastninger effektivt over systemet, og sikrer konsekvent ytelse. Den kjenner vi allerede.
- Query Processors: Utnytter PostgreSQLs meldingsbaserte protokoll og bruker Firecracker micro-VMs for å pakke PostgreSQL-motoren.
- Adjudicator: Implementerer en distribuert commit-protokoll for å håndtere isolasjon og sikre konsistens uten å kreve koordinering før COMMIT.
- Journal: Et logg-som-database-lag, som gir atomisitet og holdbarhet for transaksjonell integritet.
- Storage: Optimalisert for å minimere rundreiser mellom applikasjonen og database-motoren, med forbedret indeksering for raskere spørringsytelse.
Og vet du hva? Lesetransaksjoner i denne arkitekturen krever ingen koordinering i det hele tatt. Bare query processors som kaller lagringssystemet. Ferdig. Men for skriving må vi åpenbart koordinere. Viktig del er at koordineringen skjer ved commit-tidspunktet.

DSQL: Sikkerhet Lenke til overskrift
Himmelen for CISOs og alle som bryr seg om sikkerhet. Aurora DSQL tilbyr en secure-by-default arkitektur. Kryptering er obligatorisk for data i ro og under overføring. Og det finnes ingen måte å deaktivere det på. Jeg liker den delen. Ikke flere database-gjenskaping bare fordi noen glemte å aktivere kryptering. Og ja, ikke flere statiske passord. Det eksisterer rett og slett ikke. I det minste for forhåndsvisningen, men jeg håper det vil forbli standardalternativet. Hvis noen er kjent med RDS IAM Auth og midlertidige tokens, kan vi her se lignende oppførsel. Som bonus har vi separate IAM Actions for Admin-rolle og ikke-admin tilpassede roller.
export PGPASSWORD=$(aws dsql generate-db-connect-admin-auth-token \
--region us-east-1 \
--expires-in 3600 \
--hostname your_cluster_endpoint)
export PGSSLMODE=require
# psql use the values set in PGPASSWORD and PGSSLMODE.
psql --quiet \
--username admin \
--dbname postgres \
--host your_cluster_endpoint
Primærnøkler i Aurora DSQL Lenke til overskrift
I Aurora DSQL er det avgjørende å definere en primærnøkkel da den fungerer på samme måte som CLUSTER-operasjonen i PostgreSQL, og muliggjør effektiv datadistribusjon. Primærnøkkelen brukes til å konstruere en klyngeomfattende unik nøkkel, som sikrer skalerbarhet på tvers av lagringssystemer.
Hvis en primærnøkkel ikke defineres ved tabellopprettelse, legger DSQL automatisk til en skjult ID, og du vil ikke kunne definere en primærnøkkel senere. Unngå å bruke sekvenser som primærnøkler, da de kan føre til ujevn datadistribusjon. I stedet anbefales tilfeldige UUID-er for bedre distribusjon, selv om stigende nøkler kan fungere godt for leseintensive arbeidsbelastninger.
Husk at antall kolonner i en primærnøkkel og deres kombinerte størrelse er begrenset, så planlegg skjemaet ditt deretter for å maksimere ytelse og skalerbarhet.
PostgreSQL-funksjoner i Aurora DSQL Lenke til overskrift
Aurora DSQL holder seg tro mot PostgreSQLs røtter samtidig som den introduserer distribuerte databasekapasiteter. Navnet Aurora DSQL understreker denne forskjellen – det er ikke “Aurora Distributed PostgreSQL,” men et spesialbygd system med PostgreSQL-kompatibilitet.
For øyeblikket samsvarer DSQL tett med PostgreSQL 16, og støtter de samme verktøyene, driverne og essensielle operasjoner som SELECT, UPDATE, INSERT og DELETE. Men ikke alt fra PostgreSQL er tilgjengelig:
- Sequences og Triggers støttes ikke. Sekvenser er spesielt et kjent problem i PostgreSQLs logiske replikasjon, og krever ofte kompleks og feilutsatt synkronisering.
- Blandet DDL/DML-operasjoner støttes heller ikke, noe som er forventet siden logisk replikasjon i PostgreSQL ikke håndterer DDL-instruksjoner. Aurora DSQL håndterer disse separat for å sikre konsistens.
Til tross for disse begrensningene leverer Aurora DSQL en kjent PostgreSQL-opplevelse med skalerbarheten og ytelsen til en distribuert database.
Konkurransestyring i Aurora DSQL Lenke til overskrift
Aurora DSQL benytter en låsfri konkurransestyringsmekanisme bygget rundt snapshot isolation, som balanserer ytelse og konsistens. Ved å bruke optimistisk konkurransestyring (OCC) evalueres konflikter kun ved transaksjonscommit, noe som sikrer minimal overhead under transaksjonsforløpet. Ved konflikter prioriterer DSQL den tidligste transaksjonen og tvinger resten til å prøve på nytt. Denne tilnærmingen minimerer innholdion og sikrer høy gjennomstrømning.
Selv om konkurransestyring er et omdiskutert tema, finner Aurora DSQLs arkitektur snapshot isolation som det beste kompromisset, og gir sterk konsistens samtidig som systemet er utviklervennlig.
Denne tilnærmingen forenkler utvikling samtidig som den sikrer høy gjennomstrømning og konsistens, noe som gjør DSQL til en effektiv løsning for distribuerte arbeidsbelastninger.
Og det ser ut som AWS beveger seg i retning av sterk konsistens. MemoryDB støtter også sterk konsistens. Kanskje livet til utviklere blir mye enklere i årene som kommer.
DSQL: Bruksområder Lenke til overskrift
Aurora DSQL er designet for bransjer som krever høy tilgjengelighet, skalerbarhet og transaksjonskonsistens på tvers av distribuerte systemer. Noen viktige bruksområder inkluderer:
- Finansindustrien: Ideell for betalingstjenester, globale hovedbøker og markedsordrer. For eksempel ved lagring av finansielle transaksjoner i flere regioner. Det må være konsistent. DORA og MiCA krever at data lagres i flere regioner.
- *Helseindustrien: Håndterer pasientjournaler og logger pålitelig, selv under regionale feil, og sikrer kritisk datatilgjengelighet. Og HIPAA krever at data lagres i flere regioner.
- E-handel og detaljhandel: Støtter globale handlekurver og ordrebehandling, og sikrer at det siste varen på salg blir korrekt tildelt den første kjøperen.
- Utdanningsplattformer: Muliggjør flerregionale eksamenssystemer, og sikrer at eksamensresultater lagres selv under høy samtidighet.
Som mitt eget forslag kan jeg si at vi kan bruke mange forskjellige databasetyper selv i én applikasjon. Vi gjør det allerede for cachedata og lagrer det i Redis, større objekter i S3. Mange datalagringsmetoder for forskjellige formål er allerede her. Hvorfor ikke bruke Amazon Aurora for eksempel til å lagre brukertabeller og Amazon Aurora DSQL for finansielle transaksjoner? Hvem stopper oss fra å bruke forskjellige Aurora-typer for forskjellige formål?
Full presentasjon er tilgjengelig her.
Konklusjon Lenke til overskrift
Det var en fin tid i Singapore. Jeg var glad for å møte fellesskapet og dele min erfaring med Amazon Aurora DSQL. Jeg håper informasjonen var nyttig. Håper jeg får mulighet til å komme tilbake til Singapore og møte fellesskapet igjen.
