AWS User Group Singapore ลิงก์ไปยังหัวข้อ
ผมได้รับเชิญไปที่ AWS User Group Singapore เพื่อพูดคุยเกี่ยวกับ PostgreSQL ใน AWS และเกี่ยวกับ Amazon Aurora DSQL งานนี้เป็นงานที่ยอดเยี่ยม ผมดีใจที่ได้พบกับวิศวกรและสถาปนิกหลายคนจากชุมชน การใช้งาน PostgreSQL ในสิงคโปร์มีจำนวนมากพอสมควร ประมาณครึ่งหนึ่งของผู้ฟังใช้มัน การจัดงานเป็นไปอย่างสมบูรณ์แบบ ผมดีใจที่ได้เป็นส่วนหนึ่งของงานนี้

ประวัติเล็กๆ ของ PostgreSQL ใน AWS ลิงก์ไปยังหัวข้อ
Open-Source และ PostgreSQL ที่จัดการด้วยตัวเอง ลิงก์ไปยังหัวข้อ
ทำไมบางคนเรียก PostreSQL และบางคนเรียก Postgres? คำตอบง่ายมาก ชื่อเดิมของโปรเจกต์คือ POSTGRES ซึ่งย่อมาจาก “Post Ingres” โปรเจกต์นี้เริ่มต้นในช่วงกลางทศวรรษ 1980 โดยทีมวิจัยที่ University of California, Berkeley เพื่อเป็นผู้สืบทอดระบบฐานข้อมูล Ingres ชื่อถูกเปลี่ยนเป็น PostgreSQL เพื่อเน้นความสามารถด้าน SQL ของฐานข้อมูล
PostgreSQL ได้พัฒนาเกือบ 30 ปีจนกลายเป็นหนึ่งในฐานข้อมูลเชิงสัมพันธ์แบบ open-source ที่ได้รับความนิยมมากที่สุด ความสามารถในการขยายตัว การมีส่วนร่วมจากชุมชนทั่วโลก และการพัฒนาอย่างต่อเนื่องทำให้มันเป็นตัวเลือกยอดนิยมสำหรับแอปพลิเคชันสมัยใหม่
AWS มีบทบาทสำคัญในการขยายความสามารถของ PostgreSQL ตั้งแต่การสนับสนุนในช่วงแรกผ่าน EC2 Relational Database AMIs จนถึงการมีส่วนร่วมอย่างมากโดยเฉพาะใน logical replication และส่วนขยายอย่าง pgvector ที่ทำให้สามารถใช้ PostgreSQL เป็นฐานข้อมูลเวกเตอร์สำหรับ Amazon Bedrock ได้

จาก RDS สู่ Aurora: ยุคใหม่ ลิงก์ไปยังหัวข้อ
Amazon RDS เปิดตัวในปี 2009 โดยเริ่มจาก MySQL ก่อน ส่วนการสนับสนุน PostgreSQL มาในปี 2013 RDS แก้ปัญหาของฐานข้อมูลที่จัดการเองโดยการแนะนำฟีเจอร์ต่างๆ เช่น Multi-AZ สำหรับความพร้อมใช้งานสูง, การสำรองข้อมูลอัตโนมัติ, พื้นที่เก็บข้อมูลสูงสุด 3 TB และ 30,000 IOPS นวัตกรรมเหล่านี้ช่วยให้นักวิศวกรและสถาปนิกทั่วโลกทำงานได้ง่ายขึ้น ทำให้ PostgreSQL บน RDS เป็นตัวเปลี่ยนเกมสำหรับหลายคน
ในปี 2017 AWS เปิดตัว Amazon Aurora PostgreSQL ในยุค PostgreSQL 9.6 แม้ว่าจะมีความสงสัยในตอนแรกเนื่องจากความแตกต่างระหว่าง Aurora PostgreSQL กับ RDS สำหรับ PostgreSQL แต่การนำไปใช้ก็เติบโตอย่างต่อเนื่อง ปัจจุบันกับ PostgreSQL เวอร์ชัน 14, 16 และต่อไป Aurora PostgreSQL กลายเป็นตัวเลือกเริ่มต้นของผมสำหรับโปรเจกต์คลาวด์สมัยใหม่ หากคุณยังคิดเกี่ยวกับ Amazon RDS สำหรับ PostgreSQL หรือ Amazon Aurora PostgreSQL ผมแนะนำให้เลือก Aurora เป็นตัวเลือกเริ่มต้น
Aurora PostgreSQL นำการเปลี่ยนแปลงปฏิวัติสถาปัตยกรรม มันเป็นการแยกส่วนครั้งแรก เครื่องเก็บข้อมูลแบบ log-based ที่อนุญาตให้ใช้ headless clusters ใช่ นี่คือความจริง คุณสามารถตัดการประมวลผลทั้งหมดใน Amazon Aurora และยังคงเก็บข้อมูลไว้ได้ ฟีเจอร์สำคัญของ Amazon Aurora PostgreSQL ได้แก่:
- สถาปัตยกรรม Shared Storage: ระบบกระจายที่ทนทานต่อความผิดพลาด โดยที่ storage สามารถขยายได้แยกจาก compute
- Aurora Fast Database Cloning: ช่วยให้โคลนฐานข้อมูลได้อย่างรวดเร็วและประหยัดพื้นที่สำหรับการทดสอบและพัฒนา
- Parallel Queries และ Distributed Reads: ปรับปรุงประสิทธิภาพด้วยการรันคำสั่งแบบขนานในหลายโหนดและการกระจายงานอ่าน
- Custom Endpoints: ให้ความยืดหยุ่นในการกำหนดเส้นทางงานเฉพาะไปยังโหนดคลัสเตอร์เฉพาะ
- Point-in-Time Recovery: อนุญาตให้ผู้ใช้กู้คืนฐานข้อมูลไปยังช่วงเวลาที่กำหนด เพื่อความทนทานในกรณีเกิดภัยพิบัติ
ด้วยการแยก compute และ storage Aurora PostgreSQL ยังช่วยให้เราทดลองกับ compute instances ได้ เช่น การเปิดใช้งาน instance ประเภทต่างๆ และดูว่ามันส่งผลต่อประสิทธิภาพอย่างไร ลองใช้คลาสต่างๆ ย้ายจากอันหนึ่งไปอีกอันหนึ่ง และทั้งหมดนี้โดยไม่ต้องสร้างฐานข้อมูลใหม่
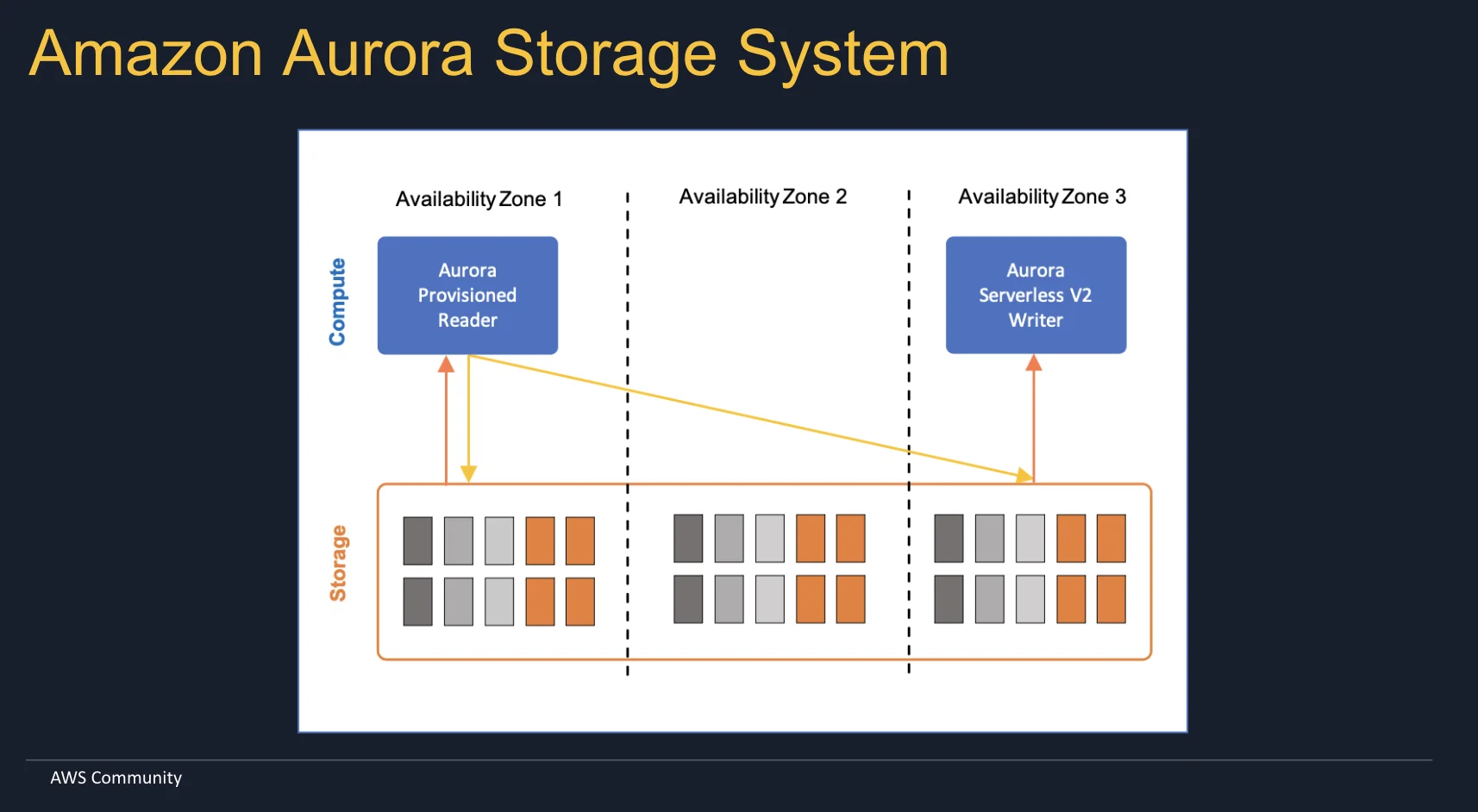
Aurora Serverless ลิงก์ไปยังหัวข้อ

Aurora Serverless ช่วยให้เราไม่ต้องกังวลเกี่ยวกับขนาดของ compute instance ของ Amazon Aurora มันเป็นเวอร์ชัน 1 แต่ตอนนี้ไม่ใช่เวอร์ชันที่ใช้งานจริงอีกต่อไป v2 เป็นเวอร์ชันเดียวที่มีให้ใช้งานและสามารถปรับขนาดลงถึง 0 ได้เช่นกัน
อย่างไรก็ตาม ค่าใช้จ่ายยังเป็นเรื่องที่ต้องพิจารณา แม้ว่าการปรับขนาดลงถึง 0 จะช่วยลดค่าใช้จ่ายในช่วงเวลาที่ไม่ได้ใช้งาน แต่ serverless v2 กลับมีราคาสูงกว่า ผมแนะนำให้เก็บข้อมูลการใช้งาน CPU จากฐานข้อมูลปัจจุบันและคำนวณค่าใช้จ่ายของ serverless v2
สำหรับผม ผมหากรณีใช้งานสำหรับ Aurora Serverless v2 ได้ และมันเหมาะกับงานที่มีโหลดไม่แน่นอน เช่น การเปลี่ยนแปลงราคาคริปโตเคอร์เรนซีจริง ในช่วงที่ตลาดพุ่งสูง Aurora Serverless v2 จะปรับขนาดแบบไดนามิกเพื่อตอบสนองความต้องการโดยไม่ต้องมีการแทรกแซงด้วยมือ
Amazon Aurora Serverless แนะนำ Request Routers ซึ่งเพิ่มเลเยอร์ที่สามในสถาปัตยกรรมของ Aurora และดำเนินการแยกส่วนต่อไป:
- Request Routers: จัดการทราฟฟิกและการเชื่อมต่อ
- Database Instances และ Compute Fleet: ทรัพยากร compute ที่ปรับขนาดได้
- Shared Storage: ทนทานและแยกจาก compute
Amazon Aurora Global Database ลิงก์ไปยังหัวข้อ
Aurora Global Database เป็นฟีเจอร์ที่ช่วยให้คุณสร้างฐานข้อมูล Aurora เดียวที่ครอบคลุมหลายภูมิภาคของ AWS ฟีเจอร์นี้เหมาะสำหรับแอปพลิเคชันที่ต้องการการเข้าถึงฐานข้อมูลที่มีความหน่วงต่ำจากหลายภูมิภาค Aurora Global Database ใช้สถาปัตยกรรม storage แบบกระจายของ Aurora เพื่อทำการจำลองข้อมูลข้ามหลายภูมิภาค อย่างไรก็ตาม การเขียนข้อมูลจำกัดอยู่ที่ภูมิภาคเดียว ในขณะที่การอ่านข้อมูลสามารถกระจายไปยังหลายภูมิภาคได้ ตั้งแต่ปี 2024 เรามี Global Writer endpoint ที่ช่วยเปลี่ยนเส้นทางการเขียนไปยังภูมิภาคที่เป็น writer
จุดสำคัญที่นี่คือ replication servers ซึ่งเป็นส่วนประกอบที่กำหนดเองอีกตัวที่ช่วยจำลองข้อมูลระหว่างภูมิภาคด้วยความหน่วงที่เราสามารถวัดได้ในระดับมิลลิวินาที ในกรณีของผมต่ำกว่า 50ms แต่สิ่งสำคัญคือเรากำลังพูดถึงมิลลิวินาที ไม่ใช่วินาที ผมคิดว่านี่ใกล้เคียงกับความเร็วของแสงมาก

Amazon Time Sync Service ลิงก์ไปยังหัวข้อ
อาจจะไม่โด่งดังมาก แต่เป็นบริการที่สำคัญมาก Amazon Time Sync Service เป็นแหล่งเวลาที่แม่นยำและเชื่อถือได้สูง ซึ่งให้เวลาปัจจุบันในรูปแบบ Coordinated Universal Time (UTC) และตั้งแต่ปีที่แล้วมันให้เวลาที่แม่นยำระดับไมโครวินาที และที่สำคัญคือมันเปิดให้ใช้งานสาธารณะ คุณสามารถใช้ในแอปพลิเคชันของคุณได้ที่: time.aws.com มาร่วมซิงโครไนซ์นาฬิกาของเราทั่วโลกกันเถอะ!
PostgreSQL 17 Logical Replication ลิงก์ไปยังหัวข้อ
ตั้งแต่ PostgreSQL 17 เราสามารถทำ major upgrade ได้โดยไม่ต้องลบ replication slots และนั่นหมายความว่าเราไม่จำเป็นต้องซิงค์ข้อมูลใหม่หลังจากอัปเกรด และสิ่งนี้เกิดขึ้นก่อน re:Invent 2024
ในปีที่แล้วผมทำงานกับ logical replication และติดตามข่าวสาร และในบางช่วงเวลาทุกอย่างก็เริ่มเข้าที่เข้าทาง การแยกส่วนของฐานข้อมูล, บริการ time sync, การปรับปรุง logical replication ไม่มีทางเลือก Google Spanner ใน AWS คุณรู้ไหม ข่าวสารทั้งหมดนี้ควรนำไปสู่สิ่งที่ยิ่งใหญ่
Amazon Aurora DSQL ลิงก์ไปยังหัวข้อ
Amazon Aurora DSQL เป็นระบบ serverless เต็มรูปแบบโดยไม่มีการจัดการโครงสร้างพื้นฐาน มันนำเสนอสถาปัตยกรรม active-active ที่มีความพร้อมใช้งาน 99.99% ในภูมิภาคเดียว และ 99.999% ในการตั้งค่าหลายภูมิภาค เพื่อความน่าเชื่อถือที่ไม่มีใครเทียบได้สำหรับงานที่สำคัญ
Aurora DSQL ถูกปรับแต่งสำหรับงานธุรกรรมที่ต้องการความสอดคล้องของ ACID transaction แตกต่างจากการตั้งค่าดั้งเดิม Aurora DSQL ขจัดปัญหาความสอดคล้องแบบ eventual consistency และ failovers
Aurora DSQL เป็นตัวเลือกที่สมบูรณ์แบบสำหรับแอปพลิเคชันสมัยใหม่ที่ต้องการฐานข้อมูลที่น่าเชื่อถือ มีความพร้อมใช้งานสูง และสามารถปรับขนาดได้
DSQL. Layers ลิงก์ไปยังหัวข้อ
Aurora DSQL ดำเนินการแยกส่วนฐานข้อมูลต่อไป แต่จริงๆ แล้วยกระดับไปอีกขั้น นี่คือสถาปัตยกรรมหลายชั้นเพื่อเพิ่มประสิทธิภาพและความสามารถในการปรับขนาดในขณะที่ยังคงความเข้ากันได้กับ PostgreSQL:
- Transaction and Session Routing: กระจายงานอย่างมีประสิทธิภาพทั่วระบบ เพื่อให้ได้ประสิทธิภาพที่สม่ำเสมอ เรารู้จักส่วนนี้ดีอยู่แล้ว
- Query Processors: ใช้โปรโตคอลแบบข้อความของ PostgreSQL และใช้ Firecracker micro-VMs เพื่อห่อหุ้มเครื่องยนต์ PostgreSQL
- Adjudicator: ใช้โปรโตคอล distributed commit เพื่อจัดการ isolation และรับประกันความสอดคล้องโดยไม่ต้องประสานงานก่อน COMMIT
- Journal: เลเยอร์ log-as-database ที่ให้ atomicity และ durability สำหรับความสมบูรณ์ของธุรกรรม
- Storage: ปรับแต่งเพื่อลดการเดินทางระหว่างแอปพลิเคชันและเครื่องยนต์ฐานข้อมูล พร้อมการจัดทำดัชนีที่ดีขึ้นเพื่อประสิทธิภาพการค้นหาที่เร็วขึ้น
และคุณรู้ไหม? ธุรกรรมอ่านในสถาปัตยกรรมนี้ไม่ต้องการการประสานงานใดๆ เลย มีแค่ query processors ที่เรียกใช้ระบบ storage เท่านั้น เสร็จแล้ว แต่สำหรับการเขียนเราต้องประสานงานแน่นอน ส่วนสำคัญคือการประสานงานเกิดขึ้นในเวลาคอมมิต

DSQL: Security ลิงก์ไปยังหัวข้อ
สวรรค์ของ CISOs และทุกคนที่ใส่ใจเรื่องความปลอดภัย Aurora DSQL มีสถาปัตยกรรมที่ปลอดภัยโดยค่าเริ่มต้น การเข้ารหัสเป็นสิ่งจำเป็นสำหรับข้อมูลที่เก็บอยู่และข้อมูลที่ส่งผ่าน และไม่มีทางปิดใช้งานได้ ผมชอบส่วนนี้ ไม่ต้องสร้างฐานข้อมูลใหม่เพียงเพราะใครสักคนลืมเปิดใช้งานการเข้ารหัส และใช่ ไม่มีรหัสผ่านแบบคงที่อีกต่อไป มันไม่มีอยู่จริง อย่างน้อยสำหรับรุ่นพรีวิว แต่ผมหวังว่ามันจะยังคงเป็นตัวเลือกเริ่มต้น ถ้าใครคุ้นเคยกับ RDS IAM Auth และโทเค็นชั่วคราว ที่นี่เราจะเห็นพฤติกรรมที่คล้ายกัน เป็นโบนัสที่เรามี IAM Actions แยกสำหรับบทบาท Admin และบทบาทที่ไม่ใช่แอดมินแบบกำหนดเอง
export PGPASSWORD=$(aws dsql generate-db-connect-admin-auth-token \
--region us-east-1 \
--expires-in 3600 \
--hostname your_cluster_endpoint)
export PGSSLMODE=require
# psql use the values set in PGPASSWORD and PGSSLMODE.
psql --quiet \
--username admin \
--dbname postgres \
--host your_cluster_endpoint
Primary keys in Aurora DSQL ลิงก์ไปยังหัวข้อ
ใน Aurora DSQL การกำหนด primary key เป็นสิ่งสำคัญเพราะมันทำหน้าที่คล้ายกับการทำงานของคำสั่ง CLUSTER ใน PostgreSQL ช่วยให้การกระจายข้อมูลมีประสิทธิภาพ Primary key ถูกใช้เพื่อสร้างคีย์ที่ไม่ซ้ำกันทั่วคลัสเตอร์ เพื่อให้สามารถปรับขนาดได้ในระบบ storage
ถ้าไม่ได้กำหนด primary key ตอนสร้างตาราง DSQL จะเพิ่ม ID ที่ซ่อนอยู่โดยอัตโนมัติ และคุณจะไม่สามารถกำหนด primary key ได้ในภายหลัง หลีกเลี่ยงการใช้ sequences เป็น primary key เพราะอาจทำให้การกระจายข้อมูลไม่สม่ำเสมอ แนะนำให้ใช้ UUID แบบสุ่มเพื่อการกระจายที่ดีขึ้น แม้ว่าคีย์ที่เพิ่มขึ้นเรื่อยๆ อาจเหมาะกับงานที่เน้นอ่านมาก
โปรดจำไว้ว่าจำนวนคอลัมน์ใน primary key และขนาดรวมของมันมีข้อจำกัด ดังนั้นวางแผน schema ของคุณให้เหมาะสมเพื่อเพิ่มประสิทธิภาพและความสามารถในการปรับขนาด
PostgreSQL Features in Aurora DSQL ลิงก์ไปยังหัวข้อ
Aurora DSQL ยังคงความเป็น PostgreSQL ในขณะที่เพิ่มความสามารถของฐานข้อมูลแบบกระจาย ชื่อ Aurora DSQL เน้นความแตกต่างนี้—มันไม่ใช่ “Aurora Distributed PostgreSQL” แต่เป็นระบบที่สร้างขึ้นมาโดยเฉพาะที่เข้ากันได้กับ PostgreSQL
ปัจจุบัน DSQL สอดคล้องกับ PostgreSQL 16 อย่างใกล้ชิด รองรับเครื่องมือ ไดรเวอร์ และการดำเนินการพื้นฐานเช่น SELECT, UPDATE, INSERT และ DELETE อย่างไรก็ตาม ไม่ใช่ทุกอย่างของ PostgreSQL ที่มีให้:
- Sequences และ Triggers ไม่ได้รับการสนับสนุน Sequences โดยเฉพาะเป็นจุดเจ็บปวดที่รู้จักใน logical replication ของ PostgreSQL ซึ่งมักต้องการการซิงโครไนซ์ที่ซับซ้อนและมีข้อผิดพลาดสูง
- การดำเนินการผสม DDL/DML ก็ไม่รองรับ ซึ่งสอดคล้องกับความคาดหวังเพราะ logical replication ใน PostgreSQL ไม่จัดการคำสั่ง DDL Aurora DSQL จัดการส่วนนี้แยกต่างหากเพื่อความสอดคล้อง
แม้จะมีข้อจำกัดเหล่านี้ Aurora DSQL มอบประสบการณ์ PostgreSQL ที่คุ้นเคยพร้อมกับความสามารถในการปรับขนาดและประสิทธิภาพของฐานข้อมูลแบบกระจาย
Concurrency Control in Aurora DSQL ลิงก์ไปยังหัวข้อ
Aurora DSQL ใช้กลไกควบคุมความขนานแบบไม่ล็อกที่สร้างขึ้นบน snapshot isolation เพื่อสร้างสมดุลระหว่างประสิทธิภาพและความสอดคล้อง โดยใช้ optimistic concurrency control (OCC) การขัดแย้งจะถูกประเมินเฉพาะในเวลาคอมมิตธุรกรรม เพื่อให้มี overhead ต่ำสุดในช่วงวงจรชีวิตของธุรกรรม ในกรณีเกิดความขัดแย้ง DSQL จะให้ความสำคัญกับธุรกรรมที่เกิดก่อนและบังคับให้ธุรกรรมอื่นลองใหม่ วิธีนี้ช่วยลดความขัดแย้งและรับประกัน throughput สูง
แม้ว่าการควบคุมความขนานจะเป็นหัวข้อที่ถกเถียงกัน สถาปัตยกรรมของ Aurora DSQL พบว่า snapshot isolation เป็นจุดที่เหมาะสม ให้ความสอดคล้องที่แข็งแกร่งในขณะที่ยังคงเป็นมิตรกับนักพัฒนา
วิธีนี้ช่วยให้ง่ายต่อการพัฒนาในขณะที่รับประกัน throughput สูงและความสอดคล้อง ทำให้ DSQL เป็นโซลูชันที่มีประสิทธิภาพสำหรับงานแบบกระจาย
และดูเหมือนว่า AWS กำลังมุ่งไปทางความสอดคล้องที่แข็งแกร่ง MemoryDB ก็รองรับความสอดคล้องที่แข็งแกร่งเช่นกัน อาจจะทำให้นักพัฒนาชีวิตง่ายขึ้นในปีต่อๆ ไป
DSQL: Use Cases ลิงก์ไปยังหัวข้อ
Aurora DSQL ถูกออกแบบมาสำหรับอุตสาหกรรมที่ต้องการความพร้อมใช้งานสูง ความสามารถในการปรับขนาด และความสอดคล้องของธุรกรรมในระบบกระจาย กรณีใช้งานสำคัญบางส่วนได้