AWS User Group Singapore Link to heading
I was invited to the AWS User Group Singapore to talk about the PostgreSQL in AWS and about the Amazon Aurora DSQL. It was a great event. I was happy to meet many engineers and architects from the community. Usuage of the PostgreSQL in Singapore is quite huge, around half of audince was using it. Organization of the event was perfect. I was happy to be a part of it.

A small history of the PostgreSQL in AWS Link to heading
Open-Source and self-managed PostgreSQL Link to heading
Why someone call PostreSQL and someone call it Postgres? The answer is simple. The original name of the project was POSTGRES, which stands for “Post Ingres.” The project was started in the mid-1980s by a team of researchers at the University of California, Berkeley, as a successor to the Ingres database system. The name was later changed to PostgreSQL to focus on the SQL capabilities of the database.
PostgreSQL has evolved over nearly 30 years into one of the most popular open-source relational databases. Its extensibility, strong community contributions from around the world, and active development have made it a go-to choice for modern applications.
AWS has played a significant role in expanding PostgreSQL’s capabilities. From its early support through EC2 Relational Database AMIs to provide huge contirubtion expesialy to logical replication and extensions like pgvector which makes possible to use PostgreSQL as is vector database for Amazon Bedrock.

From RDS to Aurora: A New Era Link to heading
Amazon RDS was released in 2009, but only MySQL. PostgreSQL support came in 2013. RDS addressed the pain points of self-managed databases by introducing features like Multi-AZ for high availability, automated backups, up to 3 TB of storage, and 30,000 IOPS. These innovations simplified the lives of engineers and architects around the globe, making PostgreSQL in RDS a game-changer for many.
In 2017, AWS introduced Amazon Aurora PostgreSQL, during the PostgreSQL 9.6 era. While it initially faced skepticism due to differences between Aurora PostgreSQL and RDS for PostgreSQL, adoption has steadily grown. Today, with PostgreSQL versions 14, 16, and beyond, Aurora PostgreSQL has become my default choice for modern cloud projects. If you still thinking about Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL, I would suggest to go with Aurora as is default option.
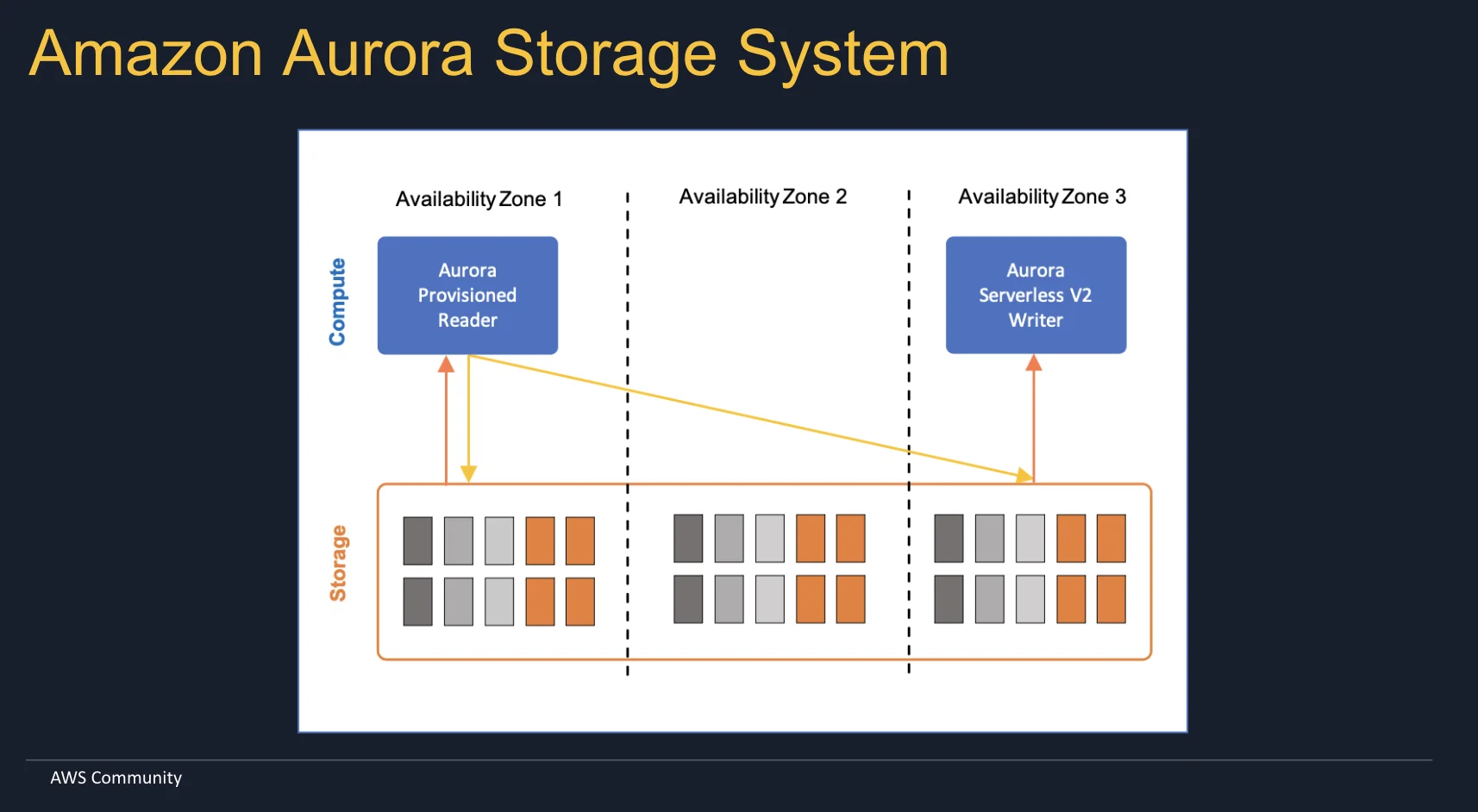
Aurora PostgreSQL brought revolutionary changes to the architecture. It was the fisrt decomposition. The log-based storage engine which allows to use headless clusters. Yes, this is real you can drop all the compute in Amazon Aurora and still retatin the data. Key features of Amazon Aurora PostgreSQL include:
- Shared Storage Architecture: A distributed, fault-tolerant system where storage scales independently of compute.
- Aurora Fast Database Cloning: Enables rapid, space-efficient clones of databases for testing and development.
- Parallel Queries and Distributed Reads: Optimized performance with queries running in parallel across multiple nodes and distributed read workloads.
- Custom Endpoints: Provide flexibility for routing specific workloads to specific cluster nodes.
- Point-in-Time Recovery: Allows users to restore databases to a specific moment in time, ensuring resilience in disaster scenarios.
By separating compute and storage, Aurora PostgreSQL also allows us to make an experiments with compute instances. Lauch different types of instances and see how it will affect the performance for example. Try different classes, migrate from one to another. And all of this whithout recreating the database.
Aurora Serverless Link to heading

Aurora Serverless brings us abitily to not think about the size of the compute instance of the Amazon Aurora. It was a version 1, but it is not actual any longer. v2 is only one which available and it able to scale to 0 as well.
Cost, however, remains a concern. While scaling to 0 can reduce expenses during idle times, serverless v2 just more expensive. I could suggest to get CPU usage metrics from the current database and calculate the cost of the serverless v2.
For me, I able to find a case for Aurora Serverless v2 and it is handling unpredictable workloads like real cryptocurrency price changes. During market spikes, Aurora Serverless v2 dynamically scales to meet demand without manual intervention.
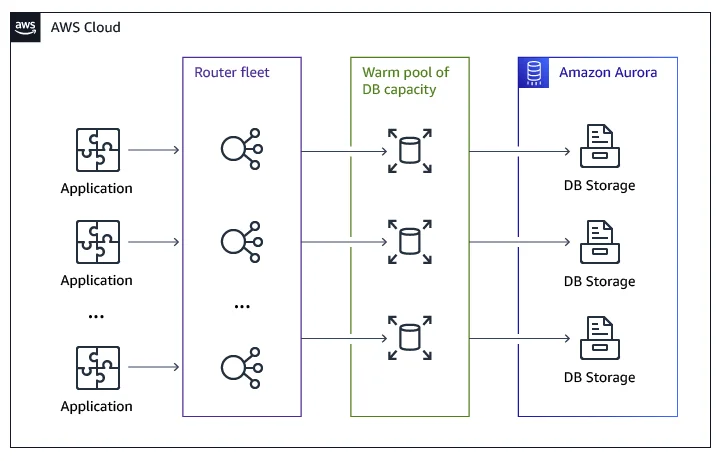
Amazon Aurora Serverless introduces Request Routers, adding a third layer to Aurora’s architecture and continue the decomposition:
- Request Routers: Handle traffic and manage connections.
- Database Instances and Compute Fleet: Scalable compute resources.
- Shared Storage: Durable and decoupled from compute.
Amazon Aurora Global Database Link to heading
Aurora Global Database is a feature that allows you to create a single Aurora database that spans multiple AWS regions. This feature is useful for applications that require low-latency access to a database from different regions. Aurora Global Database uses Aurora’s distributed storage architecture to replicate data across multiple regions. However, write operations are limited to a single region, while read operations can be distributed across multiple regions. Since 2024 we also get Grobal Writer endpoint which allows to redirect the write operations the the writer region.
Impotant moment here is replication servers. Another custom component which allows to replicate the data between the regions with latency which we could measure in milliseconds. In my case is is below 50ms. But important that we are talking about the milliseconds, not seconds. I think it is very close the speed of light.

Amazon Time Sync Service Link to heading
Maybe not that famous, but very important service. Amazon Time Sync Service is a highly accurate and reliable time source that provides the current time as Coordinated Universal Time (UTC). And since last year it provides microsecond-accurate time. And you it is actually public available. You can use it in your applications: time.aws.com Let’s synchronize our watches across the globe!
PostgreSQL 17 Logical Replication Link to heading
Since PostgreSQL 17, we able to perform major upgrade without removing the replication slots. And it means we don’t need to resync the data after the upgrade. And that one happens before the re:Invent 2024.
In the previous year I work with logical replication and follow the news and at some moment everything just start coming together. Decompositon of the database, time sync service, logical replication impovments. No Google Spanner alternative in AWS, you know, all of these news should comes to somethinb big.
Amazon Aurora DSQL Link to heading
Amazon Aurora DSQL is fully serverless with zero infrastructure management. It delivers active-active architecture, achieving 99.99% availability in a single region and 99.999% in multi-region setups, ensuring unmatched reliability for critical workloads.
Aurora DSQL is optimized for transactional workloads that require the consistency of ACID transactions. Unlike traditional setups, Aurora DSQL eliminates eventual consistency issues and failovers.
Aurora DSQL is the perfect choice for modern applications needing reliable, highly available, and scalable database solutions.
DSQL. Layers Link to heading
Aurora DSQL continues the database decomposition, but actually moving it to the next level. This a multi-layered architecture to optimize performance and scalability while maintaining PostgreSQL compatibility:
- Transaction and Session Routing: Distributes workloads effectively across the system, ensuring consistent performance. We already know that one.
- Query Processors: Leverages the PostgreSQL message-based protocol and using the Firecracker micro-VMs to wrap the PostgreSQL engine.
- Adjudicator: Implements a distributed commit protocol to manage isolation and ensure consistency without requiring coordination before COMMIT.
- Journal: A log-as-database layer, providing atomicity and durability for transactional integrity.
- Storage: Optimized to minimize round trips between the application and database engine, with enhanced indexing for faster query performance.
And you know what? Read transactions in this acrhitecture doesn’t require any coordination at all. Just query processors which call the storage system. Done. But for the writes we obviously need to coordinate. Important part that coordination happens at the commit time.

DSQL: Security Link to heading
The heaven of the CISOs and everyone who cares about the security. Aurora DSQL provides a secure-by-default architecture. Encryption is mandatory for data at rest and in transit. And there is no way to disable it. I like that part. No more database recreations just because someone forgot to enable the encryption. And yes, no more static passwords. It just not exists. At least for the preview, but I hope that it will remain the default option. If someone is familair with RDS IAM Auth and temporary tokens, here we could see the similar behavior. As bonus we got separate IAM Actions for Admin role and non-admin custom roles.
export PGPASSWORD=$(aws dsql generate-db-connect-admin-auth-token \
--region us-east-1 \
--expires-in 3600 \
--hostname your_cluster_endpoint)
export PGSSLMODE=require
# psql use the values set in PGPASSWORD and PGSSLMODE.
psql --quiet \
--username admin \
--dbname postgres \
--host your_cluster_endpoint
Primary keys in Aurora DSQL Link to heading
In Aurora DSQL, defining a primary key is crucial as it serves a similar role to the CLUSTER operation in PostgreSQL, enabling efficient data distribution. The primary key is used to construct a cluster-wide unique key, ensuring scalability across storage systems.
If a primary key isn’t defined at table creation, DSQL automatically adds a hidden ID, and you won’t be able to define a primary key later. Avoid using sequences as primary keys, as they can lead to uneven data distribution. Instead, random UUIDs are recommended for better distribution, though ascending keys may work well for read-heavy workloads.
Keep in mind that the number of columns in a primary key and their combined size are limited, so plan your schema accordingly to maximize performance and scalability.
PostgreSQL Features in Aurora DSQL Link to heading
Aurora DSQL stays true to PostgreSQL’s roots while introducing distributed database capabilities. The name Aurora DSQL emphasizes this distinction—it’s not “Aurora Distributed PostgreSQL,” but a purpose-built system with PostgreSQL compatibility.
Currently, DSQL aligns closely with PostgreSQL 16, supporting the same tools, drivers, and essential operations like SELECT, UPDATE, INSERT, and DELETE. However, not everything from PostgreSQL is available:
- Sequences and Triggers are not supported. Sequences, in particular, are a known pain point in PostgreSQL’s logical replication, often requiring complex and error-prone synchronization.
- Mixed DDL/DML operations are also unsupported, which aligns with expectations since logical replication in PostgreSQL doesn’t handle DDL instructions. Aurora DSQL manages these separately to ensure consistency.
Despite these limitations, Aurora DSQL delivers a familiar PostgreSQL experience with the scalability and performance of a distributed database.
Concurrency Control in Aurora DSQL Link to heading
Aurora DSQL employs a lock-free concurrency control mechanism built around snapshot isolation, striking a balance between performance and consistency. By using optimistic concurrency control (OCC), conflicts are evaluated only at transaction commit time, ensuring minimal overhead during the transaction lifecycle. In the case of conflicts, DSQL prioritizes the earliest transaction and force the rest to retry. This approach minimizes contention and ensures high throughput.
While concurrency control is a debated topic, Aurora DSQL’s architecture finds snapshot isolation to be the sweet spot, providing strong consistency while keeping the system developer-friendly.
This approach simplifies development while ensuring high throughput and consistency, making DSQL an effective solution for distributed workloads.
And it looks likes AWS is moving to strong consistency direction. MemoryDB is also supports strong consistency. Maybe life of developers becomes much more easier in the next years.
DSQL: Use Cases Link to heading
Aurora DSQL is designed for industries requiring high availability, scalability, and transactional consistency across distributed systems. Some key use cases include:
- Financial Industry: Ideal for payment services, global ledgers, and market orders. For example in case of saving financial transactions in multiple regions. It must be consistent. DORA and MiCA requires the data to be stored in multiple regions.
- *Healthcare Industry: Handles patient records and logs reliably, even during regional failures, ensuring critical data availability. And the HIPPA requires the data to be stored in multiple regions.
- E-Commerce and Retail: Supports global shopping carts and order processing, ensuring the last item on sale is correctly allocated to the first buyer.
- Education Platforms: Enables multi-regional exam systems, ensuring exam records are saved even during high concurrency.
As is my own suggestion, I could say, that we can use many different database types even in the one application. We alredy doing that for cache data and store it in the Redis, bigger objects in the S3. Many datastorages for different purposes methodology is already here. Why not to use Amazon Aurora for example for store the user tables and Amazon Aurora DSQL for the financial transactions? Who stops us to use different Aurora types for different purposes?
Full presentation is available here.
Conclusion Link to heading
It was a nice time in Singapore. I was happy to meet the community and share my experience with the Amazon Aurora DSQL. I hope that the information was useful. Hope I will be able to come back to Singapore and meet the community again.
